

Click the video to view more semantic annotations
TLDR: DynamicVerse is a physical-scale, multi-modal 4D modeling framework for real-world video, which contains a novel automated data curation pipeline and corresponding large-scale 4D dataset.
![]() Click to jump to each section.
Click to jump to each section.
We provide a demo video (Raw video➡️Moving Object Recovery➡️Dynamic Point Cloud) to showcase the Metric-scale 4D Reconstruction capability of DynamicGen. The generated fine-grained semantic annotations can be found at subsequent section.
The DynamicGen pipeline contains two main stages: (1) metric-scale geometric and moving object recovery (i.e., object category and mask) from raw videos, and (2) hierarchical dynamic contents (i.e., object, camera and scene) detailed caption generation. This pipeline primarily consists of five steps: 4D scene curation, data filter strategy, moving object recovery, dynamic bundle adjustment and dynamic content caption generation.

We provide visual comparison of the moving object segmentation and metric-scale geometry recovery results. We also provide dynamic point cloud reconstruction results on more in-the-wild data.

We provide a comprehensive caption at three specific levels: moving object, dynamic scene, and camera motion.

Click the video to view more semantic annotations

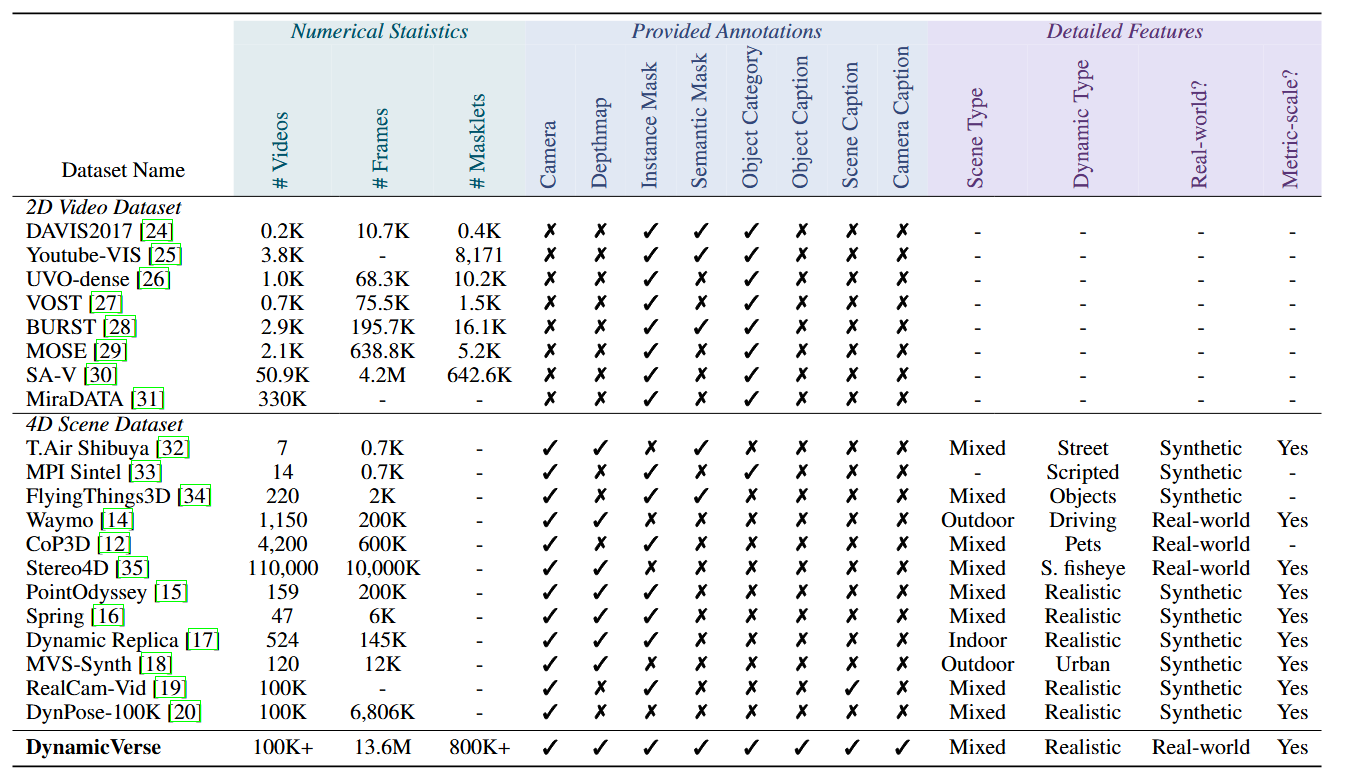
We provide the statistics and data source of DynamicVerse. We also compare DynamicVerse with large-scale 2D video datasets and existing 4D scene datasets. DynamicVerse expands the data scale and annotation richness compared to prior works.
In this work, we addressed the critical limitations in traditional 4D data curation concerning scalability, physical reality, and modality diversity. We introduced DynamicGen, a novel automated pipeline leveraging foundation models for video filtering, metric-scale geometric and moving object recovery, alongside hierarchical detailed semantic captioning from raw videos. We rigorously validated the capabilities of DynamicGen through standard benchmarks for video depth and camera pose/intrinsics estimation, qualitative generalization analysis on diverse web videos, and human/LLM-assisted evaluations confirming the high quality of the generated captions Utilizing DynamicGen, we successfully constructed DynamicVerse, a large-scale 4D dataset offering over 100K dynamic scenes with rich physically-aware multi-modal annotations. Collectively, this work provides both a robust and scalable methodology for 4D data generation and a comprehensive new resource, DynamicVerse, to drive future research in dynamic 4D scene understanding.